This is part III of our series of posts discussing Crail's raw storage performance. This part is about Crail's metadata performance and scalability.
Hardware Configuration
The specific cluster configuration used for the experiments in this blog:
- Cluster
- 8 node x86_64 cluster
- Node configuration
- CPU: 2 x Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz
- DRAM: 96GB DDR3
- Network: 1x100Gbit/s Mellanox ConnectX-5
- Software
- Ubuntu 16.04.3 LTS (Xenial Xerus) with Linux kernel version 4.10.0-33-generic
- Crail 1.0, internal version 2993
Crail Metadata Operation Overview
As described in part I, Crail data operations are composed of actual data transfers and metadata operations. Examples of metadata operations are operations for creating or modifying the state of a file, or operations to lookup the storage server that stores a particular range (block) of a file. In Crail, all the metadata is managed by the namenode(s) (as opposed to the data which is managed by the storage nodes). Clients interact with Crail namenodes via Remote Procedure Calls (RPCs). Crail supports multiple RPC protocols for different types of networks and also offers a pluggable RPC interface so that new RPC bindings can be implemented easily. On RDMA networks, the default DaRPC (DaRPC paper, DaRPC GitHub) based RPC binding provides the best performance. The figure below gives an overview of the Crail metadata processing in a DaRPC configuration.
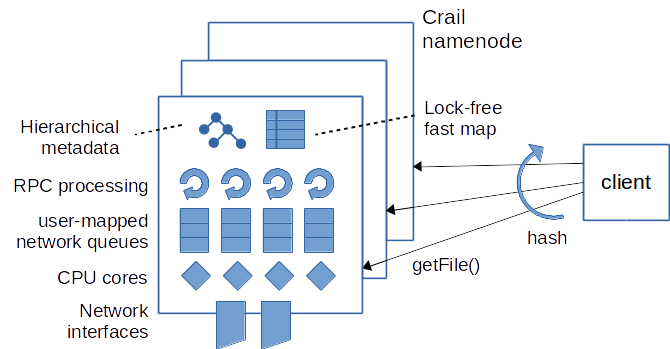
Crail supports partitioning of metadata across several namenods. Thereby, metadata operations issued by clients are hashed to a particular namenode depending on the name of object the operation attempts to create or retrieve. With the DaRPC binding, RPC messages are exchanged using RDMA send/recv operations. At the server, RPC processing is parallelized across different cores. To minimize locking and cache contention, each core handles a disjoint set of client connections. Connections assigned to the same core share the same RDMA completion queue which is processed exclusively by that given core. All the network queues, including send-, recv- and completion queues are mapped into user-space and accessed directly from within the JVM process. Since Crail offers a hierarchical storage namespace, metadata operations to create, delete or rename new storage resources effectively result in modifications to a tree-like data structure at the namenode. These structural operations require a somewhat more expensive locking than the more lightweight operations used to lookup the file status or to extend a file with a new storage block. Consequently, Crail namenodes use two separate data structures to manage metadata: (a) a basic tree data structure that requires directory-based locking, and (b) a fast lock-free map to lookup of storage resources that are currently being read or written.
Experimental Setup
In two of the previous blogs (DRAM, NVMf) we have already shown that Crail metadata operations are very low latency. Essentially a single metadata operation issued by a remote client takes 5-6 microseconds, which is only slightly more than the raw network latency of the RDMA network fabric. In this blog, we want to explore the scalability of Crail's metadata management, that is, the number of clients Crail can support, or how Crail scales as the cluster size increases. The level of scalability of Crail is mainly determined by the number of metadata operations Crail can process concurrently, a metric that is often referred to as IOPS. The higher the number of IOPS the system can handle, the more clients can concurrently use Crail without performance loss.
An important metadata operation is ''getFile()'', which is used by clients to lookup the status of a file (whether the file exists, what size it has, etc.). The ''getFile()'' operation is served by Crail's fast lock-free map and in spirit is very similar to the ''getBlock()'' metadata operation (used by clients to query which storage nodes holds a particular block). In a typical Crail use case, ''getFile()'' and ''getBlock()'' are responsible for the peak metadata load at a namenode. In this experiment, we measure the achievable IOPS on the server side in an artificial configuration with many clients distributed across the cluster issuing ''getFile()'' in a tight loop. Note that the client side RPC interface in Crail is asynchronous, thus, clients can issue multiple metadata operations without blocking while asynchronously waiting for the result. In the experiments below, each client may have a maximum of 128 ''getFile()'' operations outstanding at any point in time. In a practical scenario, Crail clients may also have multiple metadata operations in flight either because clients are shared by different cores, or because Crail interleaves metadata and data operations (see DRAM). What makes the benchmark artificial is that clients exclusively focus on generating load for the namenode and thereby are neither performing data operations nor are they doing any compute. The basic command of the benchmark as executed by each of the individual clients is given by the following command:
./bin/crail iobench -t getMultiFileAsync -f / -k 10000000 -b 128
Where ''-t'' specifies the benchmark to run, ''-f'' specifies the path on the Crail file system to be used for the benchmark, ''-k'' specifies the number of iterations to be performed by the benchmark (how many times will the benchmark execute ''getFile()'') and ''-b'' specifies the maximum number of requests in flight.
Single Namenode Scalability
In the first experiment, we measure the aggregated number of metadata operations a single Crail namenode can handle per second. The namenode runs on 8 physical cores with hyper-threading disabled. The result is shown in the first graph below, labeled ''Namenode IOPS''. The namenode only gets saturated with more than 16 clients. The graph shows that the namenode can handle close to 10 million ''getFile()'' operations per second. With significantly more clients, the overall number of IOPS drops slightly, as more resources are being allocated on the single RDMA card, which basically creates a contention on hardware resources.
As comparison, we measure the raw number of IOPS, which can be executed on the RDMA network. We measure the raw number using ib_send_bw. We configured ib_send_bw with the same parameters in terms of RDMA configuration as the namenode. This means, we instructed ib_send_bw not to do CQ moderation, and to use a receive queue and a send queue of length 32, which equals the length of the namenode queues. Note that the default configuration of ib_send_bw uses CQ moderation and does preposting of send operations, which can only be done, if the operation is known in advance. This is not the case in a real system, like crail's namenode. The basic ib_send_bw command is given below:
ib_send_bw -s 1 -Q 1 -r 32 -t 32 -n 10000000
Where ''-s 1'' specifies to send packets with a payload of 1 (we don't want to measure the transmission time of data, just the number of I/O operations), ''-Q 1'' specifies not to do CQ moderation, ''-r 32'' specifies the receive queue length to be 32, ''-t 32'' specifies the send queue length to be 32 and ''-n'' specifies the number of iterations to be performed by ib_send_bw.
The line of the raw number of IOPS, labeled ''ib send'' is shown in the same graph. With this measurement we show that Crail's namenode IOPS are similar to the raw ib_send_bw IOPS with the same configuration.

If one starts ib_send_bw without specifying the queue sizes or whether or not to use CQ moderation, the raw number of IOPS might be higher. This is due to the fact, that the default values of ib_send_bw use a receive queue of 512, a send queue of 128 and CQ moderation of 100, meaning that a new completion is generated only after 100 sends. As comparison, we did this measurement too and show the result, labeled 'ib_send CQ mod', in the same graph. Fine tuning of receive and send queue sizes, CQ moderation size, postlists etc might lead to a higher number of IOPS.
Multiple Namenode Scalability
To increase the number of IOPS the overall system can handle, we allow starting multiple namenode instances. Hot metadata operations, such as ''getFile()'', are distributed over all running instances of the namenode. ''getFile()'' is implemented such that no synchronization among the namenodes is required. As such, we expect good scalability. The graph below compares the overall IOPS of a system with one namenode to a system with two namenodes and four namenodes.

We show in this graph that the system can handle around 17Mio IOPS with two namenodes and 28Mio IOPS with four namenodes (with more than 64 clients we measured the number of IOPS to be slightly higher than 30Mio IOPS). Having multiple namenode instances matters especially with a higher number of clients. In the graph we see that the more clients we have the more we can benefit from a second namenode instance or even more instances.
We only have 7 physical nodes available to run the client processes. This means, after 7 client processes, processes start sharing a physical machine. With 64 client processes, each machine runs 9 (10 in one case) client instances, which share the cores and the resources of the RDMA hardware. We believe this is the reason, why the graphs appear not to scale linearly. The number of total IOPS is client-bound, not namenode-bound. With more physical machines, we believe that scalability could be shown much better. Again, there is absolutely no communication among the namenodes happening, which should lead to linear scalability.
Cluster sizes
Let us look at a concrete application, which ideally runs on a large cluster: TeraSort. In a previous blog, sorting, we analyze performance characteristics of TeraSort on Crail on a big cluster of 128 nodes, where we run 384 executors in total. This already proves that Crail can at least handle 384 clients. Now we analyze the theoretical number of clients without performance loss at the namenode. Still this theoretical number is not a hard limit on the number of clients. Just adding more clients would start dropping the number of IOPS per client (not at the namenode).
In contrast to the benchmarks above, a real-world application, like TeraSort, does not issue RPC requests in a tight loop. It rather does sorting (computation), file reading and writing and and of course a certain amount of RPCs to manage the files.
We would like to know how many RPCs a run of TeraSort generates and therefore how big the load in terms of number of IOPS is at the namenode for a real-world application. We run TeraSort on a data set of 200GB and measured the number of IOPS at the namenode with 4 executors, 8 executors and 12 executors. Every executor runs 12 cores. For this experiment, we use a single namenode instance. We plot the distribution of the number of IOPS measured at the namenode over the elapsed runtime of the TeraSort application.

From the graph we pick the peak number of IOPS measured throughout the execution time for all three cases. The following table shows the three peak IOPS numbers:
| #Executor nodes | Measured IOPS | % of single namenode |
|---|---|---|
| 4 | 32k | 0.32% |
| 8 | 67k | 0.67% |
| 12 | 107k | 1.07% |
From this table we see that it scales linearly. Even more important, we notice that with 12 nodes we still use only around 1% of the number of IOPS a single namenode can handle. If we extrapolate this to a 100%, we can handle a cluster size of almost 1200 nodes (1121 clients being just below 10Mio IOPS at the namenode). The extrapolated numbers would look like this:
| #Namenodes | Max IOPS by namenodes | #Executor nodes | Extrapolated IOPS | % of all namenodes |
|---|---|---|---|---|
| 1 | 10000k | 1121 | 9996k | 99.96% |
| 1 | 10000k | 1200 | 10730k | 107.3% |
| 2 | 17000k | 1906 | 16995k | 99.97% |
| 4 | 30000k | 3364 | 29995k | 99.98% |
Of course we know that there is no system with perfect linear scalability. But even if we would loose 50% of the number of IOPS (compared to the theoretical maximum) on a big cluster, Crail could still handle a cluster size of 600 nodes and a single namenode without any performance loss at the namenode. Should we still want to run an application like TeraSort on a bigger cluster, we can add a second namenode or have even more instances of namenodes to ensure that clients do not suffer from contention in terms of IOPS at the namenode.
We believe that the combination of benchmarks above, the scalability experiments and the real-world application of TeraSort shows clearly that Crail and Crail's namenode can handle a big cluster of at least several hundreds of nodes, theoretically up to 1200 nodes with a single namenode and even more with multiple namenodes.
System comparison
In this section we compare the number of IOPS Crail can handle to two other systems: Hadoop's HDFS namenode and RAMCloud.
HDFS is a well known distributed file system. Like Crail, HDFS runs a namenode and several datanodes. The namenode implements similar functionality as Crail's namenode, while HDFS's datanodes provide additional functionality, like replication, for example. We are interested in the number of IOPS the namenode can handle. As such, the datanode's functionality is not relevant for this experiment. HDFS is implemented in Java like Crail. Due to this high similarity in terms of functionality and language used to implement the system, HDFS is a good candidate to compare Crail to.
HDFS does not use RDMA to send RPCs. Instead, RPCs are sent over a regular IP network. In our case, it is the same 100Gbit/s ethernet-based RoCE network.
To measure the number of IOPS HDFS's namenode can handle, we run the same experiment as for Crail. The clients issue a ''getFile()'' RPC to the namenode and we vary the number of clients from 1 to 64. The following plot shows the number of IOPS relative to the number of clients.

The graph shows that the namenode can handle around 200000 IOPS. One reason for the difference to the number of IOPS of Crail is surely that HDFS does not use the capabilities offered by the RDMA network, while Crail does. However this cannot be the only reason, why the namenode cannot handle more than 200000 IOPS. We would need to analyze more deeply where the bottleneck is to find an answer. We believe that the amount of code which gets executed at probably various layers of the software stack is too big to achieve high performance in terms of IOPS.
RAMCloud is a fast key-value store, which makes use of the RDMA network to reach low latency and high throughput. It runs one master coordinator and and optionally several slave coordinators, which can take over, if the master coordinator fails. Coordinator persistence can be achieved by external persistent storage, like Zookeeper or LogCabin. RAMCloud runs several storage servers, which store key-value pairs in RAM. Optionally, replicas can be stored on secondary storage, which provides persistence. RAMCloud is implemented in C++. Therefore it is natively compiled code.
We are interested in the number of IOPS RAMCloud can handle. We decided to run the readThroughput benchmark of RAMCloud's ClusterPerf program, which measures the number of object reads per second. This is probably the closest benchmark to the RPC benchmark of Crail and HDFS.
For a fair comparison, we run RAMCloud without any persistence, so without Zookeeper and without replicas to secondary storage. We run one coordinator and one storage server, which is somewhat similar to running one namenode in the Crail and HDFS cases. Also, we wanted to vary the number of clients from 1 to 64. At the moment we can only get results for up to 16 clients. We asked the RAMCloud developers for possible reasons and got to know that the reason is a starvation bug in the benchmark (not in the RAMCloud system itself). The RAMCloud developers are looking into this issue. We will update the blog with the latest numbers as soon as the bug is fixed.

RAMCloud reaches a peak of 1.12Mio IOPS with 14 clients. The utilization of the dispatcher thread is at 100% already with 10 clients. Even with more clients, the number of IOPS won't get higher than 1.12Mio, because the dispatcher thread is the bottleneck, as can be seen in the graph. In addition, we got a confirmation from the developers that more than 10 clients will not increase the number of IOPS. So we think that the measurements are not unfair, even if we do not have results for more than 16 clients. Again, we we will update the blog with a higher number of clients, as soon as the bug is fixed.
Let us now summarize the number of IOPS of all three systems in one plot below. For a fair comparison, Crail runs only one namenode for this experiments and we compare the results to RAMCloud with one coordinator and one storage server (without replication as described above) and the one namenode instance of HDFS. We see that Crail's single namenode can handle a much bigger number of RPCs compared to the other two systems (remember that Crail can run multiple namenodes and we measured a number of IOPS of 30Mio/s with 4 namenodes).

HDFS is deployed on production clusters and handles real workloads with roughly 200000 IOPS. We believe that Crail, which can handle a much bigger number of IOPS, is able to run real workloads on very large clusters. A common assumption is that Java-based implementations suffer from performance loss. We show that a Java-based system can handle a high amount of operations even compared to a C++-based system like RAMCloud.
Summary
In this blog we show three key points of Crail: First, Crail's namenode performs the same as ib_send_bw with realistic parameters in terms of IOPS. This shows that the actual processing of the RPC is implemented efficiently. Second, with only one namenode, Crail performs 10x to 50x better than RAMCloud and HDFS, two popular systems, where RAMCloud is RDMA-based and implemented natively. Third, Crail's metadata service can be scaled out to serve large number of clients. We have shown that Crail offers near linear scaling with up to 4 namenodes, offering a performance that is sufficient to serve several 1000s of clients.