Crail is a high-performance distributed data store designed for fast sharing of ephemeral data in distributed data processing workloads
Fast
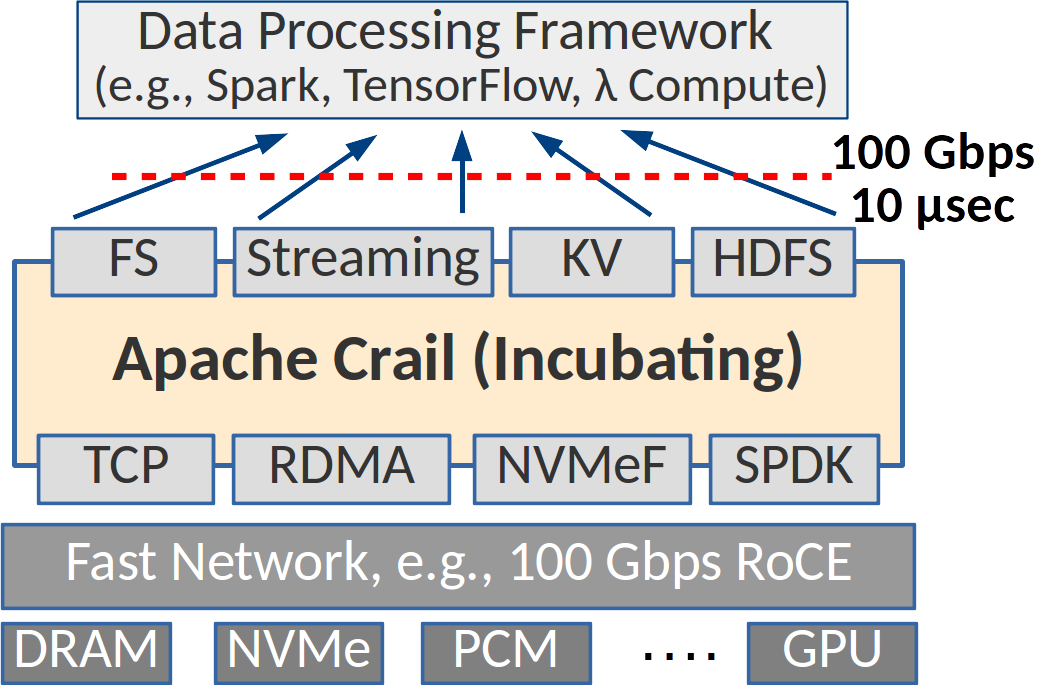
Crail is designed from ground up for modern high-performance networking and storage hardware (RDMA, NVMe, NVMf, etc.). It leverages user-level I/O to access hardware directly from the application context, providing bare-metal I/O performance to analytics workloads. For example, Crail achieves data access at rates close to the 100Gb/s network limit with latencies below 10 us.
Heterogeneous
Crail offers a unified storage namespace over a heterogeneous set of storage resources distributed in a cluster, such as DRAM, non-volatile memory (NVM), Flash or GPU memory. Depending on the storage policy, data sets may be stored on a particular storage technology or even a specific storage device, or be distributed across multiple devices and storage technologies.
Modular
Crail provides a modular architecture where new network and storage technologies can be integrated in the form of pluggable modules. Crail further exports various application interfaces including File System (FS), Key-Value (KV) and Streaming, and integrates seamlessly with the Apache ecosystem, such as Apache Spark, Apache Parquet, Apache Arrow, etc.
News
-
January 14, 2020
New release v1.2 of Apache Crail available for download
-
August 5, 2019
Paper on Crail’s system architecture was presented at USENIX ATC’19
-
June 11, 2019
Crail is now part of the YCSB benchmark suite
-
April 11, 2019
Slides from Oreilly’s Strata talk on Crail are now available
-
August 9, 2018
A new blog post discussing file formats performance is now online